Project - Quora Question Pair Similarity
Over 100 million people visit Quora every month, so it’s no surprise that many people ask similarly worded questions. Multiple questions with the same intent can cause seekers to spend more time finding the best answer to their question, and make writers feel they need to answer multiple versions of the same question. Quora values canonical questions because they provide a better experience to active seekers and writers, and offer more value to both of these groups in the long term. so main aim of project is that predicting whether pair of questions are similar or not. This could be useful to instantly provide answers to questions that have already been answered. Credits: Kaggle
Problem Statement :
Identify which questions asked on Quora are duplicates of questions that have already been asked.
Real world/Business Objectives and Constraints :
- The cost of a mis-classification can be very high.
- You would want a probability of a pair of questions to be duplicates so that you can choose any threshold of choice.
- No strict latency concerns.
- Interpretability is partially important.
Performance Metric:
- log-loss
- Binary Confusion Matrix
Data Overview:
Train.csv contains 5 columns : qid1, qid2, question1, question2, is_duplicate. Total we have 404290 entries. Splitted data into train and test with 70% and 30%.
i derived some features from questions like no of common words, word share and some distances between questions with the help of word vectors. will discuss those below. You can check my total work here and Github Link
Some Analysis:
-
Distribution of data points among output classes
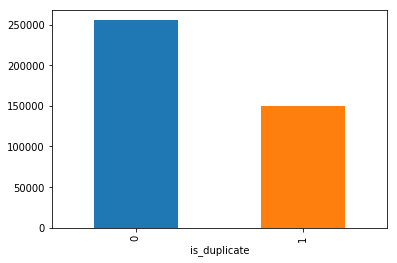
-
Number of unique questions
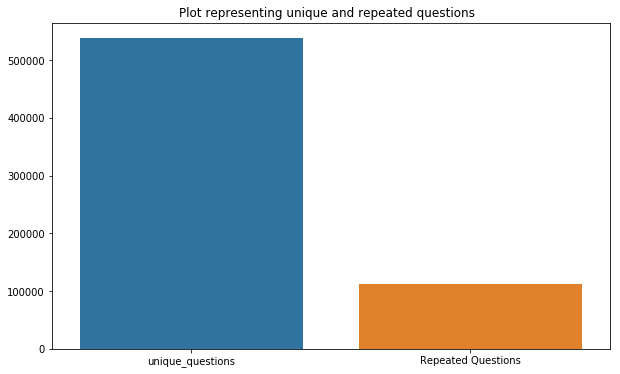
-
Number of occurrences of each question

-
There is no duplicate pairs. Have 2 Null values, which are filled with space.
-
Wordcloud for similar questions

-
Wordcloud for dissimilar questions

Feature Extraction:
-
Basic Features - Extracted some features before cleaning of data as below.
- freq_qid1 = Frequency of qid1’s
- freq_qid2 = Frequency of qid2’s
- q1len = Length of q1
- q2len = Length of q2
- q1_n_words = Number of words in Question 1
- q2_n_words = Number of words in Question 2
- word_Common = (Number of common unique words in Question 1 and Question 2)
- word_Total =(Total num of words in Question 1 + Total num of words in Question 2)
- word_share = (word_common)/(word_Total)
- freq_q1+freq_q2 = sum total of frequency of qid1 and qid2
- freq_q1-freq_q2 = absolute difference of frequency of qid1 and qid2
-
Advanced Features - Did some preprocessing of texts and extracted some other features. i am giving some definitions which are used below. Token - you get a token by splitting sentence by space , Stop_Word - stop words as per NLTK, Word - A token that is not a stop_word.
- cwc_min = common_word_count / (min(len(q1_words), len(q2_words))
- cwc_max = common_word_count / (max(len(q1_words), len(q2_words))
- csc_min = common_stop_count / (min(len(q1_stops), len(q2_stops))
- csc_max = common_stop_count / (max(len(q1_stops), len(q2_stops))
- ctc_min = common_token_count / (min(len(q1_tokens), len(q2_tokens))
- ctc_max = common_token_count / (max(len(q1_tokens), len(q2_tokens))
- last_word_eq = Check if Last word of both questions is equal or not (int(q1_tokens[-1] == q2_tokens[-1]))
- first_word_eq = Check if First word of both questions is equal or not (int(q1_tokens[0] == q2_tokens[0]) )
- abs_len_diff = abs(len(q1_tokens) - len(q2_tokens))
- mean_len = (len(q1_tokens) + len(q2_tokens))/2
- fuzz_ratio = How much percentage these two strings are similar, measured with edit distance.
- fuzz_partial_ratio = if two strings are of noticeably different lengths, we are getting the score of the best matching lowest length substring.
- token_sort_ratio = sorting the tokens in string and then scoring fuzz_ratio.
- longest_substr_ratio = len(longest common substring) / (min(len(q1_tokens), len(q2_tokens))
-
Extracted Tf-Idf features for this combained question1 and question2 and got 1,2,3 gram features with Train data. Transformed test data into same vector space.
-
Got Word Movers Distance with pretrained glove word vectors.
-
From Pretrained glove word vectors got average word vector for question1 and question2. With this avg word vector got below distances.
- Cosine distance
- Cityblock distance
- Canberra distance
- Euclidean distance
- Minkowski distance
Some Features analysis and visualizations:
-
word_share - We can check from below that it is overlaping a bit, but it is giving some classifiable score for disimilar questions.

-
Word Common - it is almost overlaping.

-
Bivariate analysis of features ‘ctc_min’, ‘cwc_min’, ‘csc_min’, ‘token_sort_ratio’. We can observe that we can divide duplicate and non duplicate with some of these features with some patterns.

-
Bivariate analysis of features ‘Word_Mover_Dist’, ‘dist_cosine’, ‘dist_cityblock’, ‘dist_canberra’,’dist_euclidean’.This also giving some patterns to classify.

Machine Learning Models:
- Trained a random model to check Worst case log loss and got log loss as 0.887699
- Trained some models and also tuned hyperparameters using Random and Grid search. I didnt used total train data to train my algorithms. Because of ram availability constraint in my PC, i sampled some data and Trained my models. below are models and their logloss scores. you can check total modelling and feature extraction here
For below table BF - Basic features, AF - Advanced features, DF - Distance Features including WMD.
| Model | Features Used | Log Loss |
|---|---|---|
| Logistic Regression | BF + AF | 0.4003415 |
| Linear SVM | BF + AF | 0.4036245 |
| Random Forest | BF + AF | 0.4143914 |
| XGBoost | BF + AF | 0.362546 |
| Logistic Regression | BF + AF + Tf-Idf | 0.358445 |
| Linear SVM | BF + AF + Tf-Idf | 0.362049 |
| Logistic Regression | BF + AF + DF + AVG-W2V | 0.3882535 |
| Linear SVM | BF + AF + DF + AVG-W2V | 0.394458 |
| XGBoost | BF + AF + DF + AVG-W2V | 0.313341 |
References:
- https://www.kaggle.com/c/quora-question-pairs
- https://www.kaggle.com/c/quora-question-pairs/discussion
- https://github.com/seatgeek/fuzzywuzzy#usage , https://chairnerd.seatgeek.com/fuzzywuzzy-fuzzy-string-matching-in-python/
- http://proceedings.mlr.press/v37/kusnerb15.pdf